The Goal of the Open Avalanche Project is to reduce avalanche-related deaths and impacts across the world. By using machine learning and experimentation to improve the accuracy and efficacy of avalanche forecasts, we are setting out to cover the world with the best Avalanche and Snow data possible.
Forecasts
Imagine the Future
Hourly Forecasts
Mountain weather can change rapidly. Conditions in an area which was not hazardous an hour ago may quickly change over the course of a day. We aim to be able to take hourly forecast and snow telemetry updates and update the forecast accordingly.
High Resolution
Most of today's avalanche forecasts are done at a regional scale. Using increased resolution, we can improve the granularity of the forecast to better account for local differences in weather and snowfall. Today we are producing forecasts at a 12km scale though we see a possibility of building local models down to 3km or smaller where the data is available if the use makes sense.
Specialized Models
We know that continental snowpack models are different than coastal models. Are there other regional differences or avalanche problems which commonly occur under certain conditions which are hard to detect or otherwise unknown? We will invest in the beginning to understand some of the broader relationships between locale and snowpack.
Forecasts in Areas Which Lack Resources
There are many forecast centers around the world but still many places which don't have the benefit of full-time avalanche forecasts. We would like to fill this gap.
A Learning Platform
The Open Avalanche Project provides a standard base to begin to build both accuracy measures and the ability to share and encode forecasting techniques across regions. What forecasters learn in Europe can directly be evaluated against US forecasting and vice versa. We can also start to measure improvements in forecasts as well as form a baseline for forecast quality. This allows increased experimentation helping us all move towards the goal of minimizing avalanche deaths.
Community Engaged
Everything about the Open Avalanche Project is designed to be transparent and available. That includes the code, the data, the financials, and the decision making process. The backcountry and snow safety communities are full of awesome and knowledgeable people we welcome you here to help make this project a place of collaboration.
We are taking the first step towards that future
- Historical avalanche forecast and weather data in a format to make machine learning experiments possible.
- A machine learning algorithm trained to predict avalanche danger based on historical data from the Northwest Avalanche Center.
- An end to end data pipeline pulling data from the three sources of the data and an operational daily forecast prediction.
How does Machine Learning Work for this?
Machine learning works by taking previous data representing examples of what we want to learn and letting a computer determine an algorithm to make those same predictions with similar inputs in the future.
In our case, the past weather, snow data is used as the training input along with the corresponding avalanche forecast information. We train the algorithm to take the input from the weather and snow information to determine the relationship between that data the avalanche forecast which is what we want to predict in the future. Once we have trained this algorithm, we can provide it additional data where we don't necessarily know the avalanche forecast and have it determine one.
Every day we pull down the most recent snow and avalanche data and use the trained algorithm to generate a new forecast.
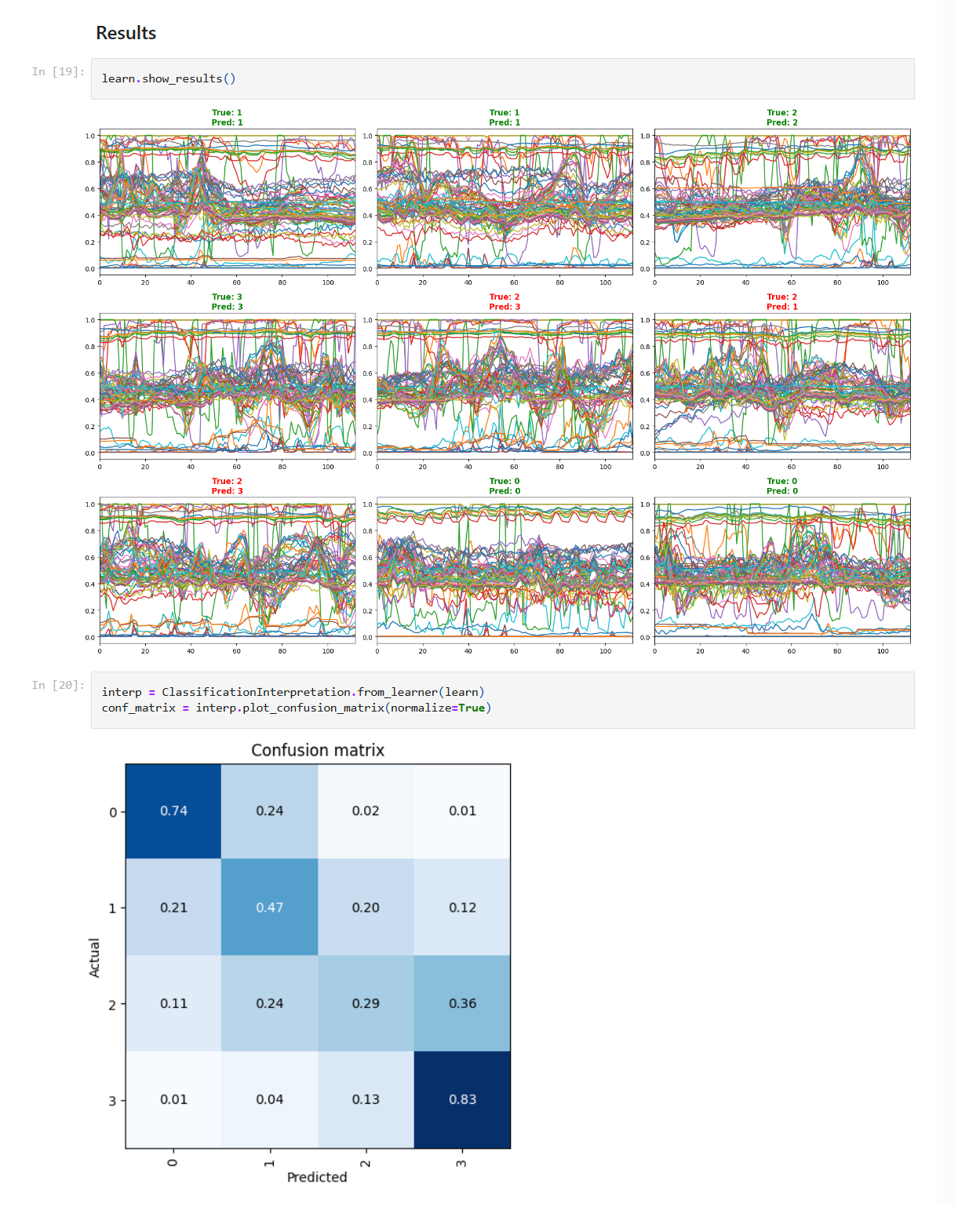
Accuracy of the Forecast
There are two methods we use to measure accuracy today:
- When training the algorithm, we hold back some of the data and don't use it as part of the training. We can then use the trained algorithm to make predictions against the held back data and then evaluate the accuracy of those predictions since we know for sure what the prediction should be. We show these accuracy evaluations along with the data on the forecast pages.
- We also want to make sure the algorithm continues to generalize into other locations and the future which is why we are currently making predictions in other areas which we haven't been trained on and are we continue to evaluate the prediction results against the daily avalanche forecasts produced. We should have those accuracy number for the 2017/2018 season available soon.
Ethics
There are two aspects to this which we should address up front: safety and people.
Safety
Avalanche forecasts are one part of a safe ski area, highway or backcountry travel evaluation. You should never use an avalanche forecast without local evidence and assessment of the snowpack. That being said, you want your forecast to be as accurate as possible and backed by confirmation against other information. Today avalanche forecasters use field reports and additional information as part of their forecasting to increase the accuracy of the information in the forecast. The Open Avalanche Project doesn't have this today, so we are only releasing these forecasts for model evaluation and development and not for hazard evaluation. It's important to start the conversation about how to better incorporate machine learning and data science techniques into this field as well as to solve some of the problems which currently exist in avalanche forecasting such as:
- How do we share data?
- How do we statistically evaluate forecasts and innovate in forecasting?
- What role does machine learning, data science, open source and open data plan in avalanche forecasting?
People
The Open Avalanche Project is committed to a people first approach. We set out to augment and improve upon the existing human capacity for the snow professionals of the world. We are committed to working with the avalanche centers around the world to have the conversation about how we can move forward on the common goal of reducing avalanche fatalities and impacts while building upon the rich legacy of innovation and safety the avalanche centers have earned.
What is possible today?
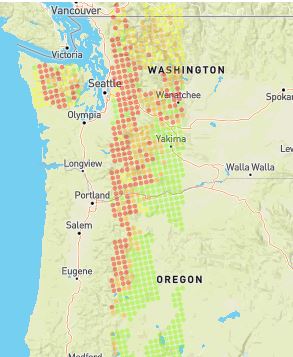
This initial release is a minimum viable product. It contains three models limited in scope to the Washington and Oregon and three models focused on the Western US. The Northwest models can be evaluated for accuracy while the Western US models cannot. We can't evaluate the accuracy of the Western US models as we don't have historical forecast information from regions outside Washington and Oregon today. We are working on collecting this data. The Western US models were primarily built to ensure the Operational aspects of the Open Avalanche Project could scale out and support our goal of world coverage. The three models only predict one thing: avalanche danger for the day of the forecast. We are now working on training models to forecasting all the avalanche problems and aspects up to four days in the future.
Contributing
The entire source code and data for the Open Avalanche Project is public and made available under the MIT license (see the Github site for more information). You are free to fork the code, train your models and ideally contribute back to the project.
Support
In support of the openness principal, I am making all the costs associated with the project public as well (see the GitHub repo). I haven't been running the live site long enough to estimate the full ongoing costs of just running the site, but I believe it will be in the several hundred dollars a month up to $5000/month if we get to global scale. I've volunteered hundreds of hours and paid several thousand dollars out of pocket to get the project to this point. Building a community is about relying on one another and I'm relying on you to help support this project. If you can do even a small part consider helping get this project off the ground by supporting the project via one of the donate links above. The future described above can only come about with community support.